
Key Takeaways
The flexibility in extending Cascading functionality provides Scale Unlimited the power to analyze a wide range of data types and allows its developers to quickly create applications in Java to complete data workflows for client projects much faster than writing in raw MapReduce.
Solution
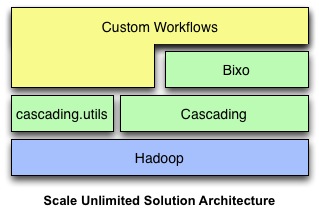
To provide big data solutions that meet these criteria, Scale Unlimited chose Apache Hadoop and Cascading. Cascading delivers the efficient, reliable and scalable workflow systems they need as well as an extensible, easy-to-use abstraction on top of Hadoop. The ability to easily extend Cascading’s input and output formats made it possible to support the wide range of required data interchange formats. Because Cascading is part of the Hadoop ecosystem, Scale Unlimited could incorporate other open source projects such as Mahout to provide additional required functionality such as machine learning.
Benefits
Cascading allows Scale Unlimited to deliver custom big data processing solutions that are efficient and reliable. It speeds development time, makes workflows easier to understand and improves workflow optimization. Developers are able to complete data workflows for client projects in ¼ the time compared to writing in raw MapReduce. Custom code can be written in Java (or other JVM-based languages), eliminating the need for Scale Unlimited or its clients to hire or train MapReduce experts. Because the resulting workflows are much easier to understand, they can be easily handed off or reused between developers as needed. Cascading also gives developers the ability to visualize workflows at a higher level, enabling them to spot optimization opportunities that would be hidden otherwise. And, Cascading manages workflows during processing, replacing ad-hoc scripts that cause reliability problems and allowing the system to scale beyond a single server.
“Cascading makes data processing with Hadoop practical, scalable and reliable,” noted Ken Krugler, Scale Unlimited’ Founder. “It allows us to quickly deliver solutions that turn big data into useful information for our customers.”
In addition to being Cascading users, Scale Unlimited has created and contributed back a number of open source Cascading-based extensions and systems, including:
- cascading.solr, for creating Solr indexes with Cascading
- cascading.avro, for reading and writing Apache Avro files
- cascading.utils, a set of utilities for Cascading workflows
- cascading.simpledb, for accessing Amazon’s SimpleDB datastore
- Bixo, a web mining toolkit, which is built on top of Cascading
Scale Unlimited will continue to use Cascading for custom big data solutions, and plans to add additional open source extensions for Cascading.